Az Excel táblázatok gyakran tartalmazzák a cellák legördülő listáit az adatok bevitelének egyszerűsítésére és / vagy szabványosítására. Ezeket a legördülő listákat az adatellenőrzési szolgáltatás segítségével hozza létre, hogy megadja a megengedett bejegyzések listáját.
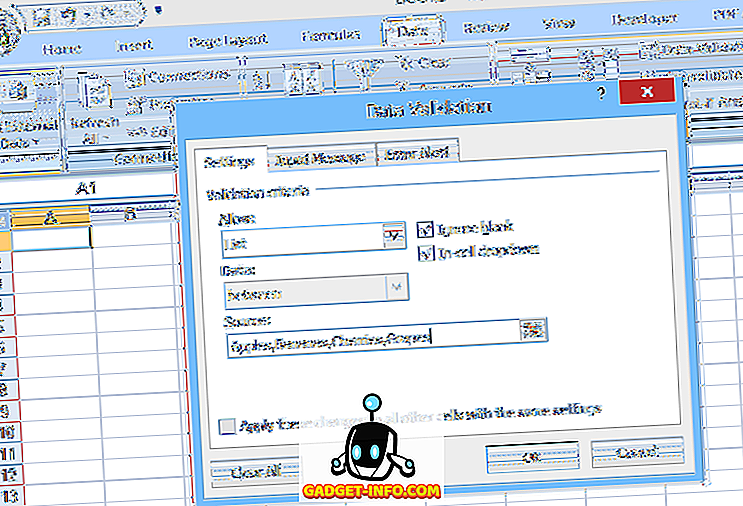
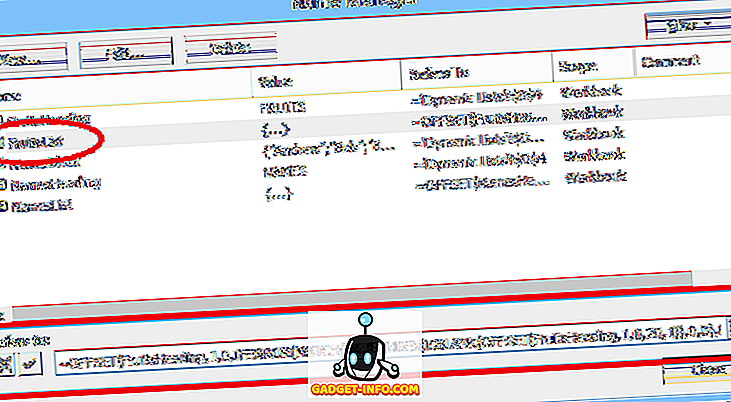
Egy egyszerű legördülő lista beállításához jelölje ki azt a cellát, ahová az adatokat beírja, majd kattintson az Adatellenőrzés gombra (az Adatok lapon), válassza az Adatellenőrzés lehetőséget, válassza a Lista (Engedélyezés :) pontot, majd adja meg a listaelemeket (vesszővel elválasztva) ) a Forrás : mezőben (lásd az 1. ábrát).
Az ilyen típusú legördülő listában az engedélyezett bejegyzések listája az adatellenőrzésen belül van megadva; ezért a lista módosításához a felhasználónak meg kell nyitnia és szerkesztenie kell az adatellenőrzést. Ez azonban nehézkes lehet a tapasztalatlan felhasználók számára, vagy olyan esetekben, amikor a választási lista hosszú.
Egy másik lehetőség az, hogy a listát a táblázatban elnevezett tartományba helyezze, majd adja meg a tartomány nevét (egyenértékű jelzéssel) az Adatellenőrzés Forrás : mezőjében (a 2. ábrán látható).
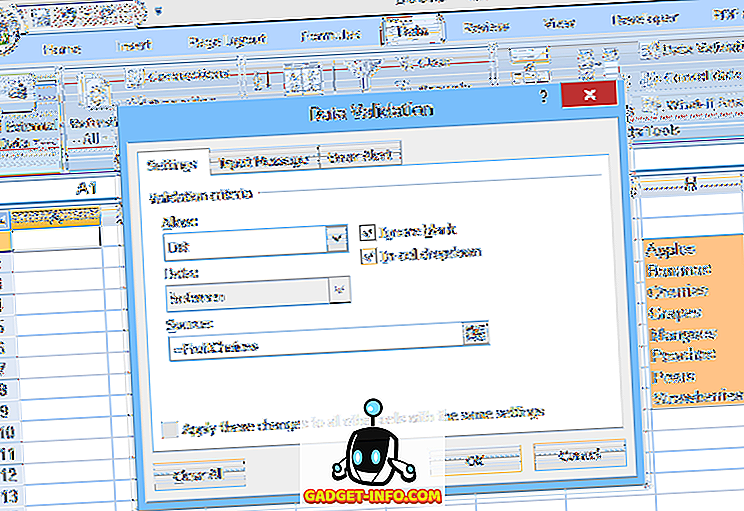
Ez a második módszer megkönnyíti a lista beállításainak szerkesztését, de az elemek hozzáadása vagy eltávolítása problémás lehet. Mivel a nevezett tartomány (FruitChoices, példánkban) egy meghatározott cellatartományra utal ($ H $ 3: $ H $ 10 az ábrán látható), ha a H11-es vagy annál alacsonyabb cellákhoz több választási lehetőség van, akkor azok nem jelennek meg a legördülő listában (mivel ezek a sejtek nem tartoznak a FruitChoices tartományba).
Hasonlóképpen, ha például a körte és a szamóca bejegyzések törlésre kerülnek, akkor azok már nem jelennek meg a legördülő listában, de a legördülő lista két „üres” választást tartalmaz, mivel a legördülő lista még mindig a teljes FruitChoices tartományra utal, beleértve az üres H9 és H10.
Ezen okokból, ha normál nevű tartományt használ egy legördülő lista listaként, akkor a nevezett tartományt szerkeszteni kell, hogy több vagy kevesebb cellát is tartalmazzon, ha a bejegyzések hozzáadódnak vagy törlésre kerülnek a listából.
Ennek a problémának az a megoldása, hogy dinamikus tartománynevet használ a legördülő választások forrásaként. A dinamikus tartománynév olyan, amely automatikusan bővíti (vagy szerződéseket), hogy pontosan illeszkedjen egy adatblokk méretéhez, mivel a bejegyzések hozzáadódnak vagy eltávolíthatók. Ehhez a megadott tartomány meghatározásához a cellák címeinek helyett inkább egy képletet használ.
Dinamikus tartomány beállítása az Excel programban
A normál (statikus) tartománynév egy meghatározott cellatartományra vonatkozik (példánkban $ H $ 3: $ H $ 10, lásd alább):
De dinamikus tartományt definiálunk egy képlettel (lásd alább, egy külön táblázatból, amely dinamikus tartományneveket használ):
Mielőtt elkezdenénk, győződjön meg róla, hogy letölti az Excel példa fájlt (a makrók rendezése le van tiltva).
Vizsgáljuk meg részletesen ezt a képletet. A Gyümölcsök választásai egy blokkban vannak, közvetlenül a címsor alatt ( FRUITS ). Ez a tétel neve is szerepel: FruitsHeading :
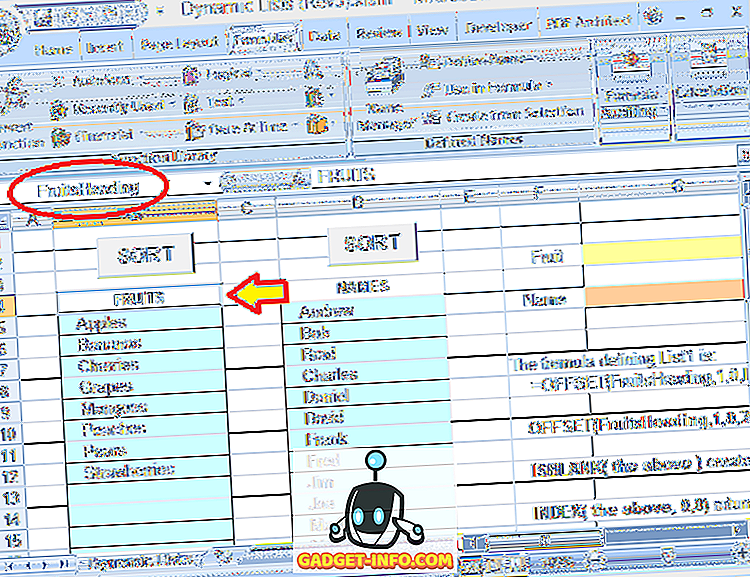
A Gyümölcsök választás dinamikus tartományának meghatározásához használt teljes képlet:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (IGAZ, INDEX (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
Gyümölcsök A fejléc olyan fejlécre utal, amely a lista első bejegyzésének egy sora. A 20-as szám (a képletben kétszer használva) a lista maximális mérete (sorok száma) (ezt a kívánt módon állíthatjuk be).
Ne feledje, hogy ebben a példában csak 8 bejegyzés szerepel a listában, de ezek alatt üres cellák is vannak, ahol további bejegyzések adhatók hozzá. A 20-as szám a teljes blokkra vonatkozik, ahol a bejegyzéseket lehet elvégezni, nem pedig a tényleges bejegyzések számát.
Most szétvágjuk a képletet darabokra (az egyes darabok színkódolása), hogy megértsük, hogyan működik:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
A „legbelső” darab OFFSET (FruitsHeading, 1, 0, 20, 1) . Ez utal a 20 sejt blokkjára (a FruitsHeading cella alatt), ahol a választások beírhatók. Ez az OFFSET funkció alapvetően azt mondja: Indítsa el a FruitsHeading cellát, menjen le 1 sor és 0 oszlop felett, majd válassza ki a 20 sor hosszú és 1 oszlop széles területet. Így megadjuk nekünk a 20 soros blokkot, ahol a Gyümölcsök választás be van írva.
A képlet következő darabja az ISBLANK funkció:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (a fenti), 0, 0), 0) -1, 20), 1)
Itt az OFFSET funkció (a fentiekben ismertetett) helyébe a „fentiek” léptek (a dolgok könnyebb olvasása). Az ISBLANK funkció azonban a 20 soros tartományban működik, amit az OFFSET funkció határoz meg.
Az ISBLANK ezután létrehoz egy 20 TRUE és FALSE értéket, jelezve, hogy az OFFSET funkció által hivatkozott 20 soros tartományban lévő egyes cellák üresek (üresek) vagy sem. Ebben a példában a készlet első 8 értéke FALSE lesz, mivel az első 8 cellák nem üresek és az utolsó 12 érték TRUE.
A képlet következő része az INDEX funkció:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (a fenti, 0, 0), 0) -1, 20), 1)
Ismét a „fentiek” a fent leírt ISBLANK és OFFSET funkciókra utalnak. Az INDEX funkció egy tömböt ad vissza, amely az ISBLANK funkció által létrehozott 20 TRUE / FALSE értéket tartalmazza.
Az INDEX- et általában arra használják, hogy egy bizonyos értéket (vagy értéktartományt) válasszon ki egy adatblokkból, megadva egy bizonyos sort és oszlopot (az adott blokkon belül). A sor- és oszlopbemenetek nullára állítása (amint itt történik) az INDEX-nek egy tömböt ad vissza, amely az egész adatblokkot tartalmazza.
A képlet következő darabja a MATCH függvény:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, a fenti, 0) -1, 20), 1)
A MATCH funkció visszaadja az első TRUE érték pozícióját az INDEX funkció által visszaadott tömbön belül. Mivel a lista első 8 bejegyzései nem üresek, a tömb első 8 értéke FALSE lesz, és a kilencedik érték TRUE (mivel a tartomány 9. sora üres).
Így a MATCH funkció visszaadja a 9 értéket. Ebben az esetben azonban valóban szeretnénk tudni, hogy hány bejegyzést tartalmaz a listában, így a képlet kivonja az 1-et a MATCH értékből (ami megadja az utolsó bejegyzés pozícióját). Így végül a MATCH (TRUE, a fenti, 0) -1 visszaadja a 8 értéket.
A képlet következő része az IFERROR funkció:
= OFFSET (FruitsHeading, 1, 0, IFERROR (a fenti, 20), 1)
Az IFERROR függvény alternatív értéket ad vissza, ha az első érték a hibához vezet. Ez a funkció azért van beépítve, mert ha a cellák teljes blokkja (mind a 20 sor) tele van bejegyzésekkel, a MATCH függvény hibát ad vissza.
Ez azért van, mert azt mondjuk a MATCH függvénynek, hogy keresse meg az első TRUE értéket (az ISBLANK függvény értékeinek tömbjében), de ha a NONE a cellák közül üres, akkor a teljes tömb FALSE értékekkel lesz kitöltve. Ha a MATCH nem találja a célértéket (TRUE) a keresett tömbben, akkor hibaüzenetet ad vissza.
Tehát, ha a teljes lista teljes (és ezért a MATCH hibát ad vissza), az IFERROR funkció helyett 20 értéket ad vissza (tudva, hogy a listában 20 bejegyzésnek kell lennie).
Végül, az OFFSET (FruitsHeading, 1, 0, a fenti, 1) visszaadja a ténylegesen keresett tartományt: Indítsa el a FruitsHeading cellát, menjen le 1 sor és 0 oszlop felett, majd válassza ki azt a területet, amely azonban sok sorban van vannak bejegyzések a listában (és 1 oszlop széles). Így a teljes képlet együtt visszaadja a tartományt, amely csak a tényleges bejegyzéseket tartalmazza (az első üres celláig).
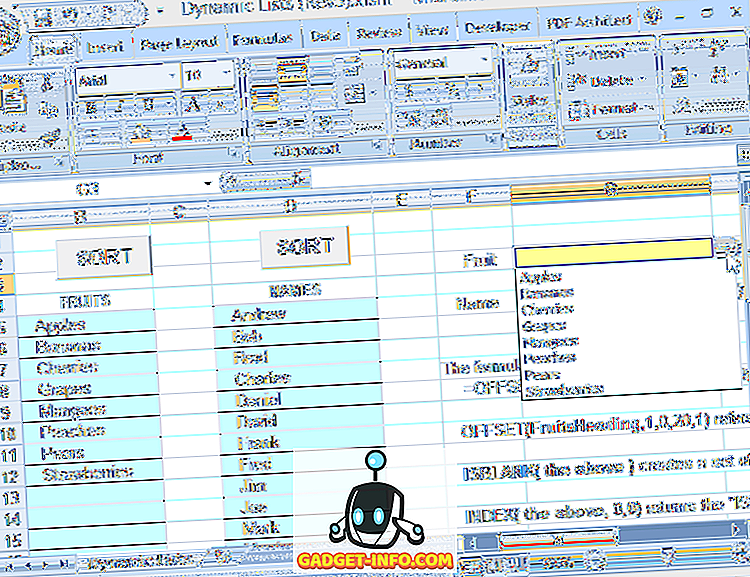
Ennek a képletnek a használatával meghatározhatja azt a tartományt, amely a legördülő forrás forrása, így szabadon szerkesztheti a listát (a bejegyzések hozzáadásával vagy eltávolításával, amíg a fennmaradó bejegyzések a felső cellából indulnak és egymás mellett vannak), és a legördülő lista mindig tükrözi az aktuális listát (lásd a 6. ábrát).
Az itt használt példafájl (dinamikus listák) a webhelyről letölthető és letölthető. A makrók azonban nem működnek, mert a WordPress nem szeret olyan makrókat tartalmazó Excel könyveket.
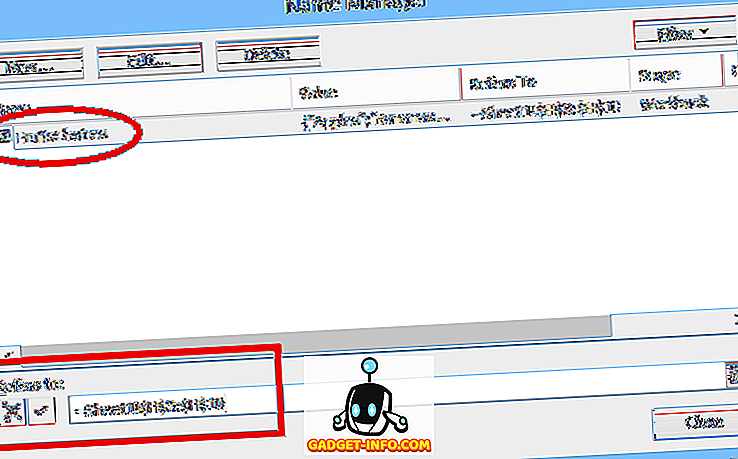
A listablokkban lévő sorok számának meghatározása helyett a listablokk saját tartománynevet is rendelhet, amelyet egy módosított képletben lehet használni. A példában a második lista (Nevek) ezt a módszert használja. Itt a teljes listablokk (a „NAMES” fejezet alatt, a példában a 40 sor) hozzárendeli a NameBlock tartomány nevét. Ekkor a Névlista meghatározására szolgáló alternatív képlet:
= OFFSET (NeveHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
ahol a NamesBlock helyettesíti az OFFSET (FruitsHeading, 1, 0, 20, 1) és a ROWS (NamesBlock) helyettesíti a 20 (sorok számát) a korábbi képletben.
Tehát a könnyen szerkeszthető legördülő listáknál (beleértve a más felhasználókat is, akik nem tapasztaltak) próbálkozzon dinamikus tartománynevek használatával! Megjegyezzük, hogy bár ez a cikk a legördülő listákra összpontosított, a dinamikus tartománynevek bárhol használhatók, ahol hivatkozni kell egy olyan tartományra vagy listára, amely mérete változhat. Élvez!